Déploiement via Terraform du cluster Docker Swarm Mode
organisation des fichiers terraform
Les fichiers terraform, (qui regroupent les ressources de l’infrastructure voulue), sont les suivants :
terraform.tf
Il s’agit du fichier de configuration principal. Il décrit l’infrastructure voulue, sous forme de ressources. Ces ressources sont fournies par des providers, et mis en place avec l’aide de provisioners afin de déployer des fichiers sur les serveurs, ou d’exécuter des commandes (locales au poste qui lance le déploiement ou distantes sur les serveurs cibles).
le fichier est organisé via les sections suivantes :
définition des providers (ici scaleway et cloudflare)
définition de la ressource “manager_init“, qui correspond au premier serveur scaleway servant à initialiser le cluster swarm (un noeud manager) : Ce premier serveur initiant le cluster est nécessaire ; il génère les tokens de sécurité pour les autres noeuds ayant le rôle de manager ou worker.
La récupération des tokens de sécurité Docker Swarm mode se fait via des appels distants vers le premier Manager sur le port 2375.
Une solution plus sûre pourrait passer plutôt par l’écriture du token sur un fichier sur le premier serveur lors de sa génération, une récupération en locale, puis un upload en scp sur les serveurs nécessitant ces tokens lors de la connexion à ceux-ci juste après leur création via des provisioners Terraform.
Veuillez noter aussi que le cluster Docker Swarm mode écoute sur le port 2375, qui n’est pas sécurisé. Une installation plus sûre utiliserait le port 2376 couplé à une authentification cliente par certificat SSL supportée nativement par le Docker Engine. Cette configuration dépasse largement le cadre de cet article.
définition des autres managers du cluster : il est recommandé, pour avoir un cluster robuste, d’avoir au moins 3 managers présents. Une plus grande robustesse aurait induit la répartition des noeuds sur plusieurs centres de données (Scaleway propose un centre de données français, et un centre de données néerlandais pour l’instant).
définition des workers du cluster
définition de l’IP statique de référence et association au serveur d’initialisation :
Cela permet que le DNS pointe toujours vers une IP valide, même si le serveur associé change. À noter qu’un problème persiste ici : lorsque le serveur tombe, il n’y a pas encore de mécanisme de rétro-contrôle qui associe l’IP avec un autre serveur en vie du cluster.
ajout d’un sous-domaine wildcard (*) au DNS, pointant vers l’IP statique Cela permet au cluster de gérer des sous-domaines de façon autonome, via traefik par exemple
définition des groupes de sécurité, avec leur règles associées : Comm indiqué précédemment, cela n’apporte qu’une sécurité limitée, au vu du fonctionnement des groupes de sécurité de Scaleway.
Ce fichier est un template pour configurer le démon docker des noeuds manager du cluster. la variable SWARM_MANAGER_PRIVATE_IP sera remplacée au démarrage pour l’adresse IP de l’interface réseau privée du serveur.
Ce fichier permet de configurer le démon des noeuds worker du cluster Docker Swarm mode. Il ne contient pas l’adresse IP de l’interface réseau privée du serveur, car les noeuds worker ne peuvent piloter le cluster (sauf si on les transforme en manager).
1
2
3
4
5
6
7
{
"experimental" : true,
"storage-driver" : "overlay2",
"labels" : ["provider=scaleway"],
"mtu": 1500,
"hosts": ["unix:///var/run/docker.sock"]
}
variables.tf
Le fichier terraform.tf, fait référence à des variables. Celles-ci sont décrites dans le fichier variables.tf.
Ce fichier est généré par Terraform, et contient l’état de l’infrastructure après application des changements.
déclenchement de Terraform
créer un plan d’exécution
l’exécution de la commande terraform plan, permet d’inspecter l’infrastructure actuelle, et l’infrastructure cible, afin de générer un plan d’exécution des changements nécessaires.
créer l’infrastructure
Cette création se fait via la commande : terraform apply
détruire l’infrastructure
La destruction se fait via la commande terraform destroy (après confirmation via l’invite de commandes).
résultat
Après avoir crée via terraform apply, votre infrastructure (et patienté quelques minutes), en se connectant sur un des noeuds ayant le rôle de manager, vous pouvez lancer la commande suivante :
1
2
3
4
5
6
7
root@swarm-manager-1:~# docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
b37dxtsbn573m4xhas0j7b4do * swarm-manager-1 Ready Active Leader
cvv0iyfy7tybsev0k55iyif4i swarm-manager-2 Ready Active Reachable
llrhva62q0byzhruu6lu29gyx swarm-worker-2 Ready Active
p4mcus11v15can4ut0lqajfqd swarm-worker-1 Ready Active
pi2wxsmibs64y9d4xwnuxvew8 swarm-manager-3 Ready Active Reachable
Vous pouvez donc constater la bonne mise en place de votre cluster Docker Swarm Mode.
conclusion
Cet article vous permet de vous familiariser avec Terraform, un outil de plus en plus présent pour automatiser la création de vos infrastructures immutables via du code. Il vous permet aussi de vous essayer à la création d’un cluster Docker Swarm Mode. J’attire néanmoins votre attention sur la non-sécurisation de l’image et du réseau mis en place.
Une mise en production d’un environnement de ce type, demanderait au préalable, d’autres opérations de sécurisation qui sortent du cadre de cet article.
Il est nécessaire d’utiliser une image, pour que le serveur Scaleway créé via Terraform puisse exécuter un système d’exploitation. Scaleway propose de réutiliser le format de docker (Dockerfile), avec quelques adaptations, pour définir sa propre image.
Pour cela, Scaleway fournit un repository github appelé image builder, permettant de construire une image iso suivant ses besoins, via un serveur Scaleway. Des images sont fournies par la communauté et validées par l’hébergeur pour être disponibles pour tous, mais on ne peut pas dire que Scaleway soit d’une grande célérité pour les valider (ubuntu et la dernière version de docker ici), ou pour les fournir.
À ce jour (avril 2017), l’image fournie ne contient que docker 1.12.2, soit 3 versions de retard… Il est donc nécessaire de construire sa propre image.
création du serveur permettant de construire son image
Un préalable est bien sûr d’avoir un compte Scaleway. La création d’un serveur de construction d’image peut être fait simplement via la ligne de commande de Scaleway appelée scw. Rappelons que la création de cette image est spécifique à cet hébergeur.
scw a été pensé pour ressembler à la ligne de commande docker. Vous retrouverez de nombreuses sous-commandes docker qui ont été reprises dans celle-ci.
Identifiez-vous au préalable sur Scaleway via scw : scw login
scw images vous permet de lister les images disponibles, tant celles de la communauté scaleway que les vôtres.
Vous retrouverez donc l’image dédiée à la construction d’images personnalisées appelée image-builder.
scw run vous permet de créer un serveur et le démarrer. Vous lancerez donc un nouveau serveur de création d’image via :
scw run --name="mon-image-perso" image-builder
À noter que la construction du serveur n’est pas instantané (quelques minutes), il faudra donc être patient.
Cette commande vous donnera de plus, une connexion ssh sur votre serveur nouvellement crée.
Sur ce serveur, exécutez :
image-builder-configure
puis identifiez-vous via votre identifiant (mail) et votre mot de passe. Cette étape préalable permettra, une fois l’image construite, de pousser l’image dans l’infrastructure Scaleway pour qu’elle soit disponible (uniquement pour notre compte), lors de la création de nouveaux serveurs (le but de ce second article).
Le serveur nouvellement crée contient 2 fichiers d’exemple qui nous intéressent : Makefile.sample et Dockerfile.sample.
Créez un répertoire dédié :
mkdir myimage copiez les fichiers d’exemple :
cp Makefile.sample myimage/Makefile
puis
cp Dockerfile.sample myimage/Dockerfile
et rentrez dans le répertoire:
cd myimage
Makefile
Ce fichier permet de définir :
le nom de l’image à construire
la version
le titre
la description
l’architecture
la taille du volume (espace disque) associé
le nom du script à exécuter lors du démarrage du noyau linux
Modifiez le fichier Makefile avec le descriptif, le nom et la version voulue.
Ce fichier permet de décrire les étapes d’installation de votre serveur, comme un fichier Dockerfile classique. Néanmoins, des commentaires sont présents dans ce fichier, qui sont indispensables pour créer l’image sur plusieurs architectures : n’y touchez pas.
contenu
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
FROM scaleway/ubuntu:amd64-16.10
# following 'FROM' lines are used dynamically thanks do the image-builder
# which dynamically update the Dockerfile if needed.
#FROM scaleway/ubuntu:armhf-16.10 # arch=armv7l
#FROM scaleway/ubuntu:arm64-16.10 # arch=arm64
#FROM scaleway/ubuntu:i386-16.10 # arch=i386
#FROM scaleway/ubuntu:mips-16.10 # arch=mips
# Prepare rootfs
RUN /usr/local/sbin/scw-builder-enter
# Add your commands here (before scw-builder-leave and after scw-builder-enter)
RUN sudo apt-get install -y \
apt-transport-https \
ca-certificates \
curl \
software-properties-common
RUN curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
Cette image dérive d’une image Ubuntu relativement récente (ici 16.10).
Un choix plus conservateur serait Ubuntu 16.04 LTS (LTS pour Long Term Support).
Notez qu’il est important de choisir une distribution ayant un noyau assez récent, car Docker s’appuie sur des fonctionnalités du noyau Linux qui se sont stabilisées que depuis peu, et évolue à la vitesse d’un cheval au galop.
Une autre alternative, qui va au bout de la démarche de “conteneurisation”, serait de choisir un système d’exploitation reposant uniquement sur des conteneurs tels rancherOS, CoreOS, Photon ou Atomic. Cela fera peut-être partie d’un prochain article. L’arrivée de LinuxKit, essayant d’être le dénominateur commun technique de ces initiatives, en est l’illustration.
description
Ce fichier Dockerfile comprend l’ajout des utilitaires nécessaires à l’ajout de la clé gpg de Docker, ainsi que le repository, puis l’installation du package docker-ce lui-même.
Le fichier docker.conf est ajouté aussi pour surcharger la configuration par défaut de docker dans systemd (en ne définissant aucune option), afin de permettre de définir par la suite (dans le troisième article), via le fichier /etc/docker/daemon.json (fichier dont l’usage est maintenant recommandé par Docker), les différentes options du démon docker, dont les ports.
Cette étape n’aurait pu être incluse dans l’image générée et donc dans ce Dockerfile, car nous incluons dans le fichier /etc/docker/daemon.json l’adresse IP privée du serveur crée, qui est dynamique.
docker.conf :
1
2
3
[Service]
ExecStart=
ExecStart=/usr/bin/dockerd
lancer la création de l’image
exécuter la commande suivante pour créer l’image : make image_on_local
Après l’exécution de la commande précédente, Vous devriez voir votre nouvelle image (à la première ligne) dans la liste de celles disponibles. via la commande :
De plus, des mécanismes de sécurité ne sont pas installés (fail2ban par exemple).
Enfin, le fonctionnement des règles des groupes de sécurité réseau de Scaleway sont pour le moins particulières (ou j’ai loupé quelque chose) :
Même si ces règles contiennent les plages IP depuis lesquels accepter le traffic (ici des IP internes 10.0.0.0/8 bien que cela ne nous prémunisse pas des autres clients Scaleway), les ports sont quand mêmes accessibles via l’extérieur….
En bref, la mise en place dans l’image (ce qui n’est pas le cas ici), d’un pare-feu (ufw, ou directement netfilter par exemple), n’acceptant que des connexions des serveurs du cluster est nécessaire au delà des quelques minutes de test de cet article.
Je regrette de plus, que scaleway ne bénéficie pas du réseau privé disponible sur l’infrastructure de la maison mère online.net (appelé RPN).
Conclusion
La définition et la construction d’une image de serveur sont facilitées par les outils fournis par Scaleway, inspirés de ceux de Docker. Malheureusement, cette image ne sera pas utilisable directement chez d’autres hébergeurs. Le troisième et dernier article réutilisera l’image créée ici, pour créer des serveurs et y déployer le cluster Docker Swarm Mode.
Dans ce premier article, voyons les caractéristiques de cette solution (n’hésitez pas à passer directement au deuxième article si vous êtes allergiques au bla-bla) : il s’agit d’une infrastructure auto-descriptive, flexible, immutable, à forte densité, résistante aux pannes.
une infrastructure auto-descriptive
Au lieu d’opérer des opérations d’installation et de configuration, de façon manuelle, et non documentée, il est indispensable de nos jours, d’utiliser des outils automatisés, reposant sur des informations textuelles, que l’on peut gérer via des systèmes de gestion de version (git par exemple). La seule lecture de fichiers doit pouvoir décrire dans son intégralité la solution mise en place.
L’infrastructure déployée doit être automatisée via du code (bye-bye les clickodromes non reproductibles). Cette tendance est appelée infrastructure as code en Anglais.
une infrastructure immutable
L’”immutabilité” (en vrai français l’immuabilité), est particulièrement à la mode en ce moment, tant au niveau de la programmation (Erlang, Scala …), que des infrastructures.
Concernant la fourniture de serveurs, dès qu’un changement doit être opéré, au lieu de modifier celui-ci, nous allons le détruire pour en recréer un autre, de façon automatisée. Cela évitera dans le temps, de ne plus maîtriser l’état du serveur ; en effet, l’installation, la mise à jour, la suppression, puis la réinstallation d’une nouvelle version d’un logiciel sur un serveur n’est souvent pas équivalent à l’installation directe de cette nouvelle version. L’état du serveur devient de moins en moins maîtrisable au cours du temps, il se dégrade.
Ainsi, des outils forts pratiques tels Ansible, Puppet ou Chef, pour ne citer que les plus connus, qui automatisent beaucoup de tâches, sont de moins en moins utilisés pour déployer des infrastructures (serveurs, DNS, réseaux etc..), car leur utilisation répétée sur ces mêmes ressources ne permet plus de maîtriser précisément leurs états au bout d’un certain temps. Néanmoins, ils restent présents concernant la finalisation quelquefois complexe des serveurs.
Cette évolution est traduite en anglais par l’expression “pets vs cattle”, c’est-a-dire la comparaison de serveurs à des animaux de compagnie (“pets”), auquel on porte une grande attention (pour faire le parallèle à la grande complexité actuelle pour maîtriser l’état de nos serveurs), à opposer au bétail (“cattle”), auquel on n’attache pas une grande importance (on n’hésite pas à recréer un serveur au lieu de le faire évoluer).
une infrastructure flexible
Concernant la flexibilité, l’appel d’APIs de fournisseurs d’infrastucture à la demande (IAAS ou infrastructure as a service) s’impose de plus en plus. Les hébergeurs peuvent être internes aux grandes entreprises avec des déploiements de centre de données VMWare par exemple, ou externes avec des fournisseurs tels Amazon Web Services (AWS), Digital Océan, ou Scaleway dans cette série d’articles. Cette flexibilité permet d’ajuster son infrastructure en temps réel au gré de ses besoins.
une infrastructure à haute densité
L’usage tendant à se généraliser des conteneurs, principalement Docker, permet de faciliter et standardiser l’installation de logiciels, et de densifier les serveurs. En effet, l’installation de multiples conteneurs sur un même serveur, permet de rentabiliser au mieux l’usage des serveurs : de nombreux logiciels se côtoient sans effets de bords notables (mise à part une concurrence accrue sur l’usage des ressources serveurs).
infrastructure résistante aux pannes
Une infrastructure résistante au pannes sera distribuée et redondée sur plusieurs serveurs (voire plusieurs centre de données), afin de pallier à une défaillance de l’un d’entre eux.
et concrètement du côté de la technique ?
Docker Swarm Mode
L’usage de conteneurs Docker tend à se généraliser pour standardiser le déploiement d’applications. Les différents conteneurs devant intéragir pour former des applications (serveur web, base de données etc…), différentes solutions d’orchestration existent. J’ai choisi pour cet article une solution récente et simple : docker swarm mode.
Elle n’est pas aussi mûre que Mesos, ni la plus complète (Kubernetes), mais est une des plus simples (avec Cattle un des orchestrateurs supportés par Rancher).
Terraform
Nous utiliserons Terraform, une solution de description et de construction d’infrastructure immutable. Celle-ci comprend de nombreux fournisseurs (providers), dont scaleway pour les serveurs, et cloudflare pour le DNS.
Scaleway
J’ai choisi l’hébergeur français Scaleway, filiale de Online, pour son coût modique, et la présence d’un “provider” Terraform. Cette solution est encore assez jeune, et fournit un niveau très basique d’équipement à la demande, contrairement à sa maison mère (pas de réseau privé virtuel RPN ici par exemple).
Cloudflare
J’ai choisi d’utiliser cloudflare pour gérer le nom de domaine, car celui-ci fournit ce service gratuitement, et permet d’inclure une étoile (wildcard), comme sous-domaine, permettant que tous les sous-domaines soient redirigés vers le cluster Docker Swarm Mode.
Conclusion
Les différentes propriétés décrites dans ce premier article, permettent je l’espère de vous faire comprendre l’intérêt des outils mis en oeuvre.
Passons maintenant à la lecture du deuxième article pour passer à la mis en oeuvre.
Cette série d’articles essaie de vous faire découvrir des outils bien utiles autour de Apache Kafka.
Le premier outil est kafkacat, un outil en ligne de commande qui permet facilement et rapidement de lire et d’écrire dans des topics kafka.
outils fournis par apache kafka
Le projet open source Apache Kafka propose une série d’outils pour intéragir avec cette plateforme de streaming distribuée ultra-performante : ceux-ci font partie intégrante du projet.
Pour les utiliser, il est nécessaire de récupérer le projet sur github, et de lancer ces scripts qui lancent des machines virtuelles Java. Ces outils sont les plus aboutis et complets. Néanmoins, pour des besoins simples, il est pratique d’utiliser des interfaces en ligne de commande (CLI).
intérêt de kafkacat
Kafkacat est une interface en ligne de commande. Elle permet donc d’être chaînée, afin de filtrer les messages lus, rediriger le flux vers un fichier, ou vers d’autres outils Linux.
#installation
Des packages sont disponibles dans la plupart des distributions Linux. Sous Ubuntu, il faut lancer :
sudo apt-get install kafkacat
un horizon des commandes kafkacat
afficher l’aide
Pour afficher l’aide, il suffit de lancer :
kafkacat -h
afficher la version
Pour afficher la version, il suffit de lancer :
kafkacat -V
structure d’une commande kafkacat
une commande kafkacat s’exécute toujours de la façon suivante :
kafacat -b host:port -mode -modeoptions
Il est indispensable de spécifier évidemment un ou des brokers kafka auxquels se connecter, via l’attribut -b.
Celui-ci doit être complété par le mode avec les valeurs suivantes :
-L pour lire les méta-données du cluster kafka (topics, nombre de partitions etc..)
-C pour lire les messages
-P pour produire les messages
options générales
les options suivantes sont présentes dans tous les modes :
-b pour spécifier l’hôte et le port des brokers kafka de la forme host1:port1;host2:port2,host3:port3
-t pour spécifier le topic
-c pour limiter le nombre de message produits ou lus
-p pour spécifier la partition
-G pour spécifier le groupe de consommateurs
-X pour spécifier des options à la librairie libdrdkafka C sous-jacente à kafkacat
-K pour spécifier le délimiteur de la clé (optionnelle) d’un message
-D pour spécifier le délimiteur de la valeur d’un message
-q pour que kafkacat soit silencieux
-d pour permettre le débugging via la librairie libdrdkafka
lire les métadonnées du cluster
Lister les topics présent dans un broker se fera via la commande suivante :
kafkacat -b 127.0.0.1:9092 -L
et donnera ce type de résultat :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
Metadata for all topics (from broker 1: 127.0.0.1:9092/1):
1 brokers:
broker 1 at 127.0.0.1:9092
3 topics:
topic "Topic2" with 1 partitions:
partition 0, leader 1, replicas: 1, isrs: 1
topic "test-compact" with 1 partitions:
partition 0, leader 1, replicas: 1, isrs: 1
topic "Topic1" with 1 partitions:
partition 0, leader 1, replicas: 1, isrs: 1
Indiquant :
la liste des brokers avec leur identifiant
la liste des topics
pour chaque topic, les partitions
pour chaque partition le broker hébergeant la partition leader, les brokers hébergeant les réplicas, et le nombre de réplicas synchronisés (isrs)
lire des messages
Kafka stocke ses messages dans des topics, qui contiennent une ou plusieurs partitions. Les message sont toujours lus du plus ancien au plus récent, et ont un ordre garanti au sein d’une même partition.
kafkacat -b mybroker:9092 -C -t mytopic
Cette commande permet de lister les messages présents dans le topic mytopic, mais ne se terminera pas : kafkacat restera en écoute de nouveaux messages.
lire des messages et quitter
Afin de terminer la commande après avoir lu les messages, il faut ajouter l’option -e -pour exit) : kafkacat -b mybroker:9092 -C -t mytopic -e
lire des messages depuis un offset donné
Par défaut, kafkacat lit les messages du topic depuis les offsets les plus récents de chaque partition. Néanmoins, on peut spécifier à partir de quel offset on souhaite lire le topic via l’argument -o. Les valeurs possibles sont :
lira les messages du topic depuis le plus ancien message encore stocké pour chaque partition (le message peut disparaître plus ou moins rapidement en fonction des règles de suppression configurées dans kafka).
end
kafkacat -b host:port -C -t mytopic -o end
lira les futurs messages à partir du dernier message stocké pour chaque partition au moment de l’interrogation de kafka.
Y coupler -e n’aura pas trop de sens, car la commande sortira avant d’avoir pu récupérer un nouveau message.
stored
A la place de spécifier en option l’offset à partir duquel lire les messages, kafkacat peut lire l’offset de début de lecture pour chaque partition via une autre source de données :
Permettra de lire les messages de ce topic depuis les offsets désignés pour chaque partition. Si le répertoire est vide, kafkacat créera les fichiers nécessaires pour stocker ces offsets (de la forme topicname-partition*.offset). Le dernier offset lu sera sauvegardé toutes les 250 millisecondes.
L’offset est stocké dans un topic spécial, utilisé par kafka pour connaître les derniers offsets de chaque partition de chaque topic, pour chaque groupe de consommateurs. Il est donc nécessaire de passer à kafka l’identifiant du groupe de consommateurs pour qu’il puisse identifier quel dernier message vous avez lu.
valeur positive
kafkacat -b host:port -C -t mytopic -o 31559 -e
lira les messages depuis l’offset 31559 de toutes les partitions jusqu’à la fin du topic au moment de l’interrogation de kafka.
valeur négative
Il est possible de lire (approximativement), par exemple les 1500 derniers messages d’un topic (sur l’ensemble des partitions), en lançant la commande suivante :
kafkacat -b host:port -C -t mytopic -o -1500 -e
lire des messages sur une partition donnée
Il est possible de lire sur une partition donnée via -p, avec la commande suivante :
Ne seront retournés que les messages du topic stockés dans la partition numéro 4.
lire des messages avec un groupe de consommateurs donné
Il est possible de lire des messages en tant que membre d’un groupe de consommateurs avec la commande suivante :
kafkacat -b host:port -C -t mytopic -G mygroup -e
Kafka nous assignera des partitions du topic à lire (toutes les partitions si nous sommes le seul membre actif du groupe), et nous délivrera les messages à partir des derniers offsets lus pour chaque partition.
lire des messages avec un format de sortie personnalisé
Il est possible de produire des messages depuis plusieurs fichiers, chacun contenant un seul message. Même si ces fichiers contiennent des séparateurs, le contenu de chaque fichier sera considéré comme un seul message.
Comme évoqué auparavant, kafkacat repose sur la librairie C libdrdkafka.
Certaines versions de cette librairie ont pour comportement par défaut d’intéragir avec le protocole de kafka dans une certaine version; ce comportement par défaut ne correspond pas toujours à la version de kafka que vous utilisez. Il faut donc spécifier via des paramètres libdrdkafka (option -X)le protocole à utiliser. Ainsi, quand on lit un kafka 0.10.1.0 avec kafkacat 1.3.0-1 on peut obtenir l’erreursuivante :
1
2
3
4
5
%4|1480463638.946|PROTOERR|rdkafka#consumer-1| 127.0.0.1:9092/9092: Protocol parse failure at rd_kafka_fetch_reply_handle:3864 (incorrect broker.version.fallback?)
Kafkacat ne permet pas toutes les intéractions permises par les outils intégrés dans le projet Kafka.
La principale cause est l’absence de toutes les fonctionnalités de ces outils dans le protocole d’interaction avec Kafka. De nombreuses avancées arrivent de version en version, mais des manques persistent.
création et suppression de topics
Kafka 0.10.1.0 intègre dans son protocole la création et la suppression de topics. Kafkacat 1.3.0 n’intègre pas cette fonctionnalité qui est prévue pour la version 1.4.0.
recherche par timestamp
Cette fonctionnalité est aussi apparue dans la version 0.10.1.0 de kafka. Elle n’est pas encore supportée par kafkacat.
support de la compression lz4
La compression lz4, ajoutée en complément des compressions gzip et snappy, a été implémentée dans kafkacat mais n’est pas encore présent dans le paquet distribué par ubuntu.
Il conviendra donc de compiler depuis les sources kafkacat, avec une version plus récente de la librairie libdrdkafka pour supporter ce nouvel algorithme.
conclusion
Kafkacat me semble être un bon outil en ligne de commande, permettant d’interagir de façon performante avec kafka, et de s’intégrer aux autres lignes de commandes Linux via le chaînage des commandes.
Néanmoins, il s’avère dans certains cas indispensable d’avoir une version récente de kafkacat, ou de passer par les outils fournis avec kafka.
Cette série de deux articles décrit le fonctionnement de la librairie de visualisation de logs webappender.
Le premier article expose sa mise en place, et les différentes façons de visualiser les logs suivant son navigateur.
Le deuxième article décrit la façon de choisir le contenu et la taille des logs à afficher.
Personnaliser le contenu des logs
La librairie webappender, permet de personnaliser le contenu de chaque log. par défaut, toutes les informations disponibles via logback sont incluses.
Néanmoins, certaines informations peuvent être longues à récupérer. Webappender permet donc de ne pas aller chercher et inclure ces informations, si le header HTTP X-wa-verbose-logs=false est transmis.
Ainsi, seront exclues de chaque log, les informations suivantes :
Avec cette configuration, le temps d’exécution des requêtes est donc moins impactés lorsque le webappender est activé.
Filtrer les logs
Webappender, supporte les filtres logback, pour réduire les traces applicatives (logs) transmises à votre navigateur.
Veuillez noter que ces filtres ne sont appliqués que dans le contexte de webappender, c’est-à-dire dans les informations transmises dans la réponse HTTP.
Ce filtrage ne s’applique, comme toujours, qu’aux traces liées aux requêtes faites par votre navigateur. Les traces ne sont pas filtrées dès leur création, comme pourrait le faire les filtres turbo.
Cette série de deux articles décrit le fonctionnement de la librairie de visualisation de logs webappender.
Le premier article expose sa mise en place, et les différentes façons de visualiser les logs suivant son navigateur.
Le deuxième article décrit la façon de choisir le contenu et la taille des logs à afficher.
Le problème
Pour des applications web, il est courant de d’effectuer la recette des fonctionnalités sur des serveurs distants.
Quand un comportement non attendu survient, il est nécessaire de retracer le fonctionnement précis de l’application, notamment via l’inspection des traces applicatives aussi appelées logs.
Le serveur étant distant, il est souvent nécessaire :
de se connecter en ssh sur le bon serveur
d’identifier le répertoire hébergeant les logs
d’identifier le bon fichier de logs
de démêler les logs correspondants à son test, des autres logs
Ces opérations ne sont pas instantanées et rébarbatives.
Webappender
Afin d’éviter toutes ses étapes, j’ai créer le webappender, afin que les traces serveur issues de vos requêtes HTTP arrivent directement dans votre navigateur.
Ainsi, les autres logs des requêtes exécutées de façon concurrente sur le serveur, ne sont pas envoyées vers votre navigateur. Le développeur regarde donc uniquement les informations qui sont liées à son test.
Mise en place dans votre application web JEE
Pré-requis
Webappender est compatible avec les applications JEE utilisant la librairie de logs logback. L’adhérence entre webappender et JEE est minime. Une compatibilité plus large est donc possible.
Installation en 2 étapes
Maven
Ajouter à votre fichier Maven pom.xml cette dépendance :
1
2
3
4
5
<dependency>
<groupId>com.clescot</groupId>
<artifactId>webappender</artifactId>
<version>1.4</version>
</dependency>
Notez qu’un filtre de servlet, installé par annotation, est fourni avec la librairie. Son urlPatterns correspond à toutes les requêtes (/*).
Activer le webappender
Par défaut, webappender est désactivé .
Permettre de visualiser les logs de chacun (par une interception du réseau), peut être très risqué et dangereux dans des environnements de production.
Donc, pour prévenir toute erreur de configuration, nous désactivons par défaut le webappender.
Pour l’activer, vous devez mettre ce paramètre sur la ligne de commande qui lance votre serveur d’applications : -Dwebappender=true.
Visualisation des logs
La librairie webappender permet de visualiser les logs de sa requête dans tous les navigateurs. Les visualisations de logs dans les configurations suivantes, impliquent une installation de webappender dans votre application JEE utilisant logback, avec un serveur d’applications java actif.
Vos logs dans Chrome via ChromeLogger
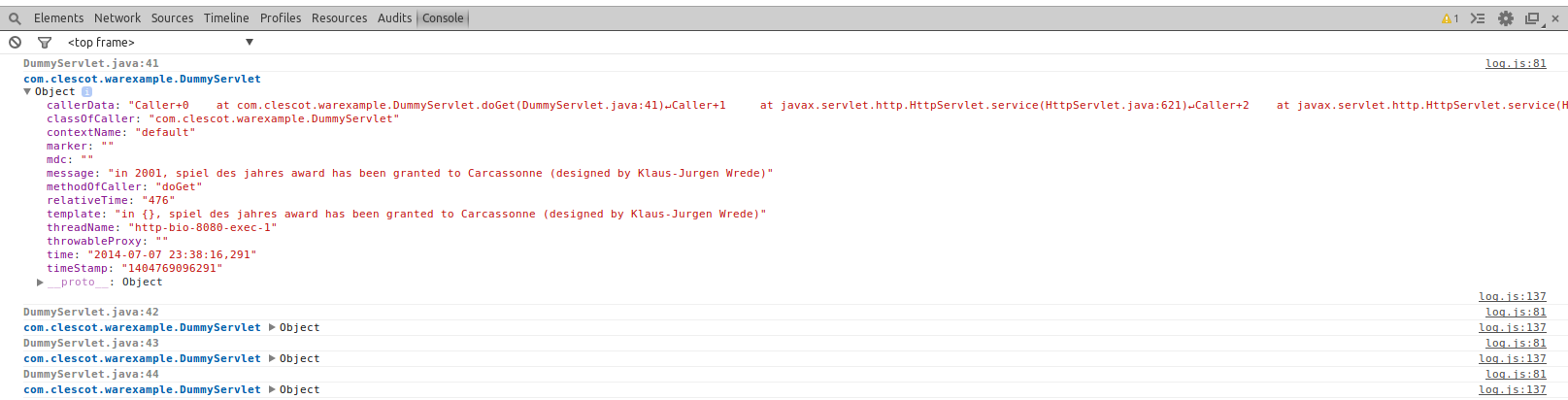
Vous devez installer le plugin chrome intitulé ChromeLogger.
Malheureusement, Chrome logger ne transmet par défaut aucun header l’identifiant, contrairement à d’autres plugins.
Or, Webappender transmet les logs à votre navigateur, quand les requêtes contiennent un header spécial : X-ChromeLogger.
Veuillez noter que cette extension envoie à chaque requête, que vous soyiez sur votre site web avec webappender ou non, les entêtes spécifiques que vous avez rajouté. La publication des entêtes spécifiques vers les serveurs est donc très large.
Une alternative à Modify Headers for Google Chrome, est l’extension ModHeader, qui permet par site de définir les headers à modifier ou rajouter.
Quand l’installation et la configuration de cette nouvelle extension est effective, appuyez sur la touche F12 de votre clavier, pour visualiser le panel console de Chrome. Cela vous montrera les logs engendrées par votre navigation sur la webapp.
Voici le détail de ce qu’une log contient :
Vos logs dans Firefox via FireLogger
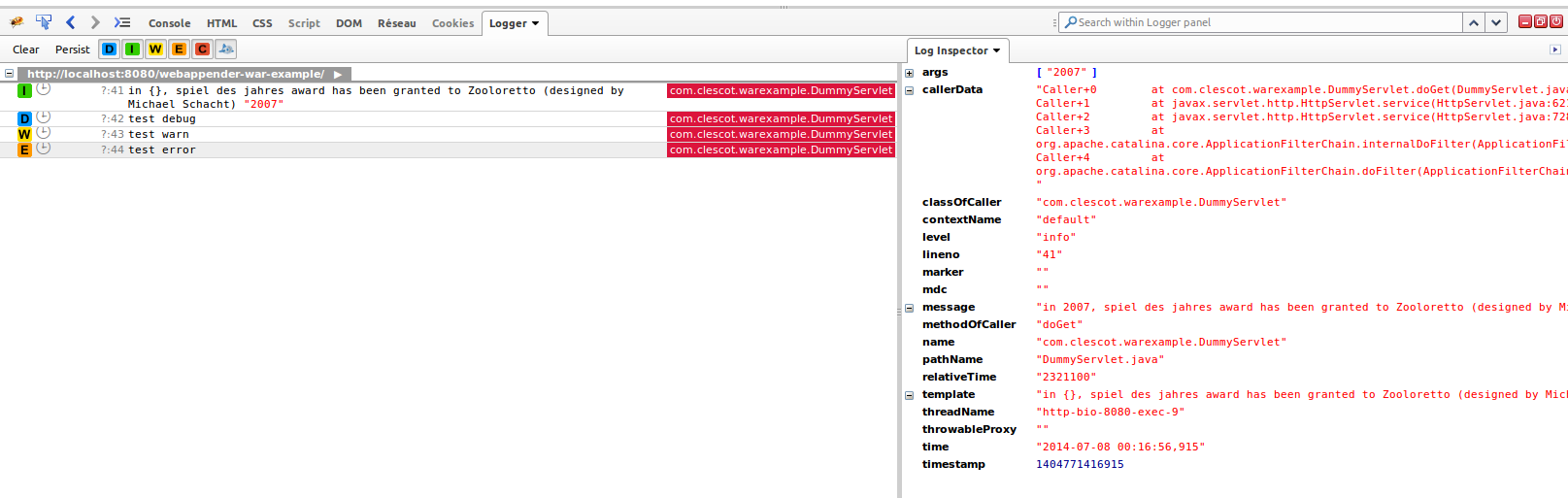
Vous devez installer le plugin firefox intitulé FireLogger.
Quand cela est fait, appuyez sur la touche F12, pour visualiser le panneau firebug ; vous devriez voir un nouvel onglet intitulé logger.
Il vous montrera vos logs, suivant leur niveau. Les logs sont transmis à votre navigateur, quand les requêtes contiennnent une entête spéciale construite par le plugin ‘FireLogger’ : X-FireLogger.
Vos logs dans n’importe quel navigateur
Si vous ne pouvez ou ne voulez pas installer un plugin firefox ou chrome, ou si vous n’avez aucun de ces navigateurs, vous pouvez tout de même visualiser vos logs dans n’importe quel navigateur. Dans ce cas, vous devez configurer un body formatter.
Pour cela, il faut :
transmettre au serveur une entête spéciale : X-BodyLogger, via une extension comme modify headers (disponible sur chrome ou firefox), ou tout autre plugin compatible avec votre navigateur ayant la possibilité d’ajouter à façon une entête spéciale.
Pour Internet Explorer, une solution gratuite comme Fiddler permet de modifier les entêtes HTTP.
installer au début de vos JSP, la declaration de la taglib, et à la fin de vos JSP, le tag webappender. Si vous utilisez une librairie de templating (comme sitemesh par example), une unique insertion dans un decorateur global aura un effet sur toutes vos JSP.
Les logs sont présentes dans le corps de la requête et non l’entête, (2Gb semble être la limite pour le corps d’une requête HTTP) ; il n’y a donc pas de réel problème de taille de logs
cela fonctionne sur tous les navigateurs
Inconvénients de cette méthode :
cela modifie le corps de votre requête
il n’y a pas de visualisation soignée de ces logs contrairement aux plugins présentés précédemment
vous ne pouvez pas filtrer vos logs du côté navigateur
Test avec une webapp exemple
Vous pouvez tester l’application de démo, qui illustre les fonctionnalités de la librairie webappender.
Aller à l’adresse suivante http://127.0.0.1:8080/webappender , et visualiser les logs en fonctions du navigateur choisi, et des entêtes transmises.
Conclusion
La librairie webappender, permet relativement simplement, de visualiser dans son navigateur, les logs générées par sa requête côté serveur. Webappender peut être installée, sur des applications JEE utilisant logback.
Les applications développées comportent inévitablement des bugs. L’erreur étant humaine, cet état de fait ne surprend plus grand monde.
Pour parer à cette situation, sont développés en parallèle toutes sortes de tests, dont les tests unitaires. Nécessaires mais non suffisants, ceux-ci sont généralement les plus rapides à s’exécuter, permettant d’avoir un feeback rapide. Leur intérêt n’est plus à démontrer.
Il est navrant en 2014, que des bugs détectés en amont par des tests se propagent.
Une vérification par une chaîne d’intégration continue centralisée ?
Le premier réflexe pour régler ce problème, est d’utiliser les outils déjà en place. Un des outils qui s’est généralisé, est une chaîne d’intégration continue centralisée, type jenkins. Cela permet de détecter un bug quand l’exécution des tests unitaires du build échoue.
Cette solution permet d’éviter de propager des bugs en production, l’équipe ne livrant que si le traitement sur la chaîne d’intégration continue s’exécute avec succès.
Néanmoins, la vérification par la chaîne d’intégration centralisée ne prévient pas la propagation du bug aux autres membres de l’équipe qui travaillent sur la même branche”, car le code a été poussé sur le repository distant. Les autres développeurs et jenkins se synchronisent ensuite sur ce même repository déjà buggé.
Le feedack vers l’équipe est donc trop tardif ! Essayons de trouver une autre approche, permettant d’avoir un feedback beaucoup plus court.
Une vérification par une chaîne d’intégration continue décentralisée !
Le but de cette approche, est de contrôler au plus tôt le code, avant de le propager au sein de l’équipe. Ce contrôle doit s’effectuer avant tout partage.
Un hook sur push
J’utilise depuis quelques semaines, une solution chez un client permettant d’exécuter les tests unitaires via Maven (mvn clean test) lors de la commande git push.
Depuis la version 1.8.2 de git apparue en mars 2013, le déclenchement d’un hook est maintenant possible sur un push. Un Hook (crochet en français ?), est un moyen d’exécuter un script personnalisé à certains moments (commit, push, merge, etc..). Il s’exécute avant l’action en question, et conditionne l’exécution de celle-ci.
Au passage, vous pouvez connaître votre version de git en exécutant la commande git --version.
Les hooks sont situés dans le sous-répertoire hooks du répertoire caché .git de votre repository. Des exemples de hook, finissant par sample sont déjà présents.
J’utilise le hook défini par itty bitty labs, en exécutant les tests unitaires via maven :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
#!/bin/bash
CMD="mvn clean test"# Command that runs your tests
# Check if we actually have commits to push
commits=`git log @{u}..`
if [ -z "$commits" ]; then
exit 0
fi
current_branch=$(git symbolic-ref HEAD | sed -e's,.*/\(.*\),\1,')
$CMD
RESULT=$?
if [ $RESULT-ne 0 ]; then
echo"failed $CMD"
exit 1
fi
exit 0
Placez ce script intitulé pre-push dans le répertoire hooks.
Ayant des tests d’intégration qui peuvent être longs, seuls les tests unitaires sont exécutés à chaque push. Ainsi, {“le Hook sur push permet d’éviter la propagation des bugs vers les autres membres de l’équipe, mais bloque le développement lors de son exécution”}.
Pour résumer, cette solution :
ne s’enclenche que sur un git push
est bloquante
Elle s’adapte bien à mon usage, car il peut m’arriver d’effectuer des commit sur une branche, en cassant des tests unitaires de façon transitoire lors de refactorings. Néanmoins, il existe des situations où il est préférable de désactiver un hook.
Sa solution est à base de hook git sur un commit. Ce hook clone le repository local dans un répertoire caché , et exécute les tests avant de valider le commit. En cas de succès, il propage le code sur le repository local initial.
Le hook sur commit permet une détection des bugs très tôt, et ne perturbe pas la fluidité du développement.
Pour résumer, cette solution :
est basée sur un hook déclenché sur un commit
est non-bloquante
Ainsi, elle permet de ne pas attendre le résultat des tests pour continuer à développer.
La solution de David Gageot, permet un contrôle plus tôt par rapport au hook sur git push, avec pour contrepartie la nécessité d’effectuer des commits plus rigoureux.
Il ne faut donc pas sortir des clous lors de chaque commit, quitte à exceptionellement désactiver le hook via l’option no-verify citée plus haut (option valide sur tous les hooks).
Effectivement, les commits sous git étant fréquents, il pourrait être désagréable d’être bloqué en attendant le résultat de tests unitaires de nombreuses fois par jour. La solution du clone du repository local dans un répertoire caché est une solution élégante, car elle permet de ne pas être bloqué dans ses développements.
Conclusion
Si vous êtes très rigoureux, utilisez donc la solution proposée par David Gageot. Si vous n’êtes pas en situation de le faire sur votre projet, peut-être que l’approche hook sur git push répondra à votre besoin. J’espère qu’un de ces hooks vous permettra d’éviter la propagation de bugs vers vos collègues.
Je vous propose dans cette série de 4 articles, de vous présenter la librairie Metrics, initié par la société Yammer. Celle-ci permet de fournir des métriques au niveau applicatif et JVM.
Ce quatrième article, présente l’intégration de Metrics avec les drivers JDBC, logback et jersey.
avec les drivers JDBC
La librairie JDBCMetrics intégre JDBC avec Metrics. Cela permet :
d’avoir une vision globale de la charge de la base de données issue de votre application
d’avoir une vision précise du nombre et des performances des requêtes SQL pour chaque requête HTTP
Pour rajouter ce module à votre application, il faut rajouter la dépendance suivante à votre fichier maven pom.xml:
1
2
3
4
5
<dependency>
<groupId>com.soulgalore</groupId>
<artifactId>jdbcmetrics</artifactId>
<version>1.1</version>
</dependency>
La vision globale de la charge de la base de données induite par l’application est possible via la configuration du driver JDBC, soit via un Datasource (la librairie jouant le rôle de proxy), soit via le DriverManager.
Au passage DriverManager est une classe dépréciée, ayant un comportement incohérent au niveau du chargement du driver. Préférez donc le Datasource.
La vision précise de la charge au niveau base de données par requête HTTP, est permise de façon optionnelle via l’installation d’un servlet filter :
Metrics fournit une librairie d’intégration avec logback, pour remonter des informations concernant la fréquence des évenements logués suivant le niveau de log.
Pour intégrer Metrics et logback, il faut rajouter la dépendance suivante dans votre fichier pom.xml :
1
2
3
4
5
6
7
<dependencies>
<dependency>
<groupId>com.codahale.metrics</groupId>
<artifactId>metrics-logback</artifactId>
<version>3.0.1</version>
</dependency>
</dependencies>
Voici le code à utiliser pour lier Metrics à logback.
1
2
3
4
5
6
7
final LoggerContext factory = (LoggerContext) LoggerFactory.getILoggerFactory();
final Logger root = factory.getLogger(Logger.ROOT_LOGGER_NAME);
final InstrumentedAppender metrics = new InstrumentedAppender(registry);
metrics.setContext(root.getLoggerContext());
metrics.start();
root.addAppender(metrics);
Une application concrète de cette intégration pourrait être une surveillance d’évenements logués en erreur ou warning, afin de réagir rapidement quand ceux-ci surviennent avec une fréquence importante.
Voici comment installer une mesure concernant les logs ayant le niveau error dans logback :
A noter qu’une intégation avec log4J existe aussi.
avec Jersey
Pour intégrer les mesures de Metrics avec les services REST exposés via Jersey et Spring, il est nécessaire d’intégrer le module suivant à votre fichier pom.xml :
1
2
3
4
5
<dependency>
<groupId>com.yammer.metrics</groupId>
<artifactId>metrics-jersey</artifactId>
<version>3.0.1</version>
</dependency>
Sérialisation du registre Metrics en JSON via jackson
Le module maven metrics-json, permet de sérialiser facilement les mesures au format JSON, via des modules Jackson dédiés.
l’ajout de la dépendance suivante dans votre pom.xml permet de les utiliser :
1
2
3
4
5
<dependency>
<groupId>com.codahale.metrics</groupId>
<artifactId>metrics-json</artifactId>
<version>3.0.1</version>
</dependency>
De plus, vous devez créer une ressource REST, qui va exposer la représentation JSON de votre registre Metrics comme dans l’exemple suivant :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
@Path("/")
publicclassFooResource{
privatestaticfinal ObjectMapper mapper = new ObjectMapper().registerModules(
new com.codahale.metrics.json.MetricsModule(TimeUnit.SECONDS, TimeUnit.MILLISECONDS, false),new HealthCheckModule());
private MetricRegistry registry;
@Inject
publicFooResource(MetricRegistry registry){
this.registry = registry;
}
@Path("/metrics")
@GET
@Produces(MediaType.APPLICATION_JSON)
public String serializeMetricsRegistryInJSON()throws JsonProcessingException {
return mapper.writeValueAsString(registry);
}
}
Ainsi, cette ressource JAX-RS exposera sur l’url http://monhost:8080/metrics en GET une représentation JSON du registre Metrics.
Une exposition de ces métriques peut être utile, pour par exemple, une page de supervision habillant ces métriques avec du javascript.
conclusion
La librairie Metrics est très pratique. Son usage s’est largement répandu, ce qui se traduit par la présence de librairies tierces afin d’enrichir son usage. Les 4 articles de cette série vous ont permis j’espère, de vous familiariser avec cette librairie. J’ai mis en place cette solution chez un de mes clients, en envoyant les informations de Metrics vers un serveur Graphite, pour une historisation pérenne, et un travail à postériori sur les métriques techniques ou fonctionnelles remontées.
Afin de distinguer les métriques des différents environnements (poste de développement, recette, pre-production, production…), remontées vers le même serveur, j’ai mis en place un ServletContextListener qui configure au démarrage de l’application le reporter Graphite en fonction de variables positionnées au lancement du serveur. Les métriques seront donc présentes dans graphite dans des arborescences séparées, via un préfixe différent.
Je vous propose dans cette série de 4 articles, de vous présenter la librairie Metrics, initié par la société Yammer. Celle-ci permet de fournir des métriques au niveau applicatif et JVM.
Ce troisième article, présente l’intégration de Metrics avec les librairies d’injection de dépendances Spring et Guice.
Metrics avec Spring et Guice
Le deuxième article de cette série consacrée à Metrics, présentait une intégration “legacy” de Metrics dans une application JEE.
Néanmoins, Il existe des librairies qui intègrent facilement Metrics à Spring ou Guice. L’avantage de ces librairies, est qu’elles permettent de simplifier l’usage de Metrics, via des annotations. Les applications utilisant maintenant principalement les containers d’injection de dépendances, votre configuration ressemblera plutôt à un des exemples présentés ci-après.
Avec Spring
Une librairie tierce permet l’intégration facile de Metrics avec les applications utilisant Spring (cette librairie supporte, au moment où j’écris l’article, la version 3.x de Metrics, contrairement à la librairie intégrant Metrics et Guice).
Au choix, soit la configuration via un fichier XML, soit par des annotations permet d’intégrer les deux librairies. Cette configuration nous permettra d’annoter nos classes hébergeant les métriques.
Il faut rajouter la dépendance suivante à votre fichier maven pom.xml :
1
2
3
4
5
<dependency>
<groupId>com.ryantenney.metrics</groupId>
<artifactId>metrics-spring</artifactId>
<version>3.0.1</version>
</dependency>
la configuration Spring via xml
La configuration en xml, de l’intégration des deux librairies se fait comme suit :
Comme indiqué dans les commentaires du xml précédent (issu de la documentation du module d’intégration), la déclaration du registre et des reporters doit être réalisée dans un seul fichier xml, tandis que la balise liée aux annotations doit être présente dans chaque fichier xml spring.
la configuration Spring via des annotations
De façon alternative, l’intégration se réalise en javaConfig comme suit :
L’application utilise Metrics 3.0.1, via une librairie metrics-guice qui n’a pas encore de version stable (à l’heure où j’écris cette article) supportant Metrics 3.x. J’ai donc forké le repository de metrics-guice pour juste upgrader la dépendence de Metrics vers la version 3.0.1. Un repository metrics-guice dépendant de Metrics 3.0.1 a été crée pour cette occasion.
Classiquement, l’intégration de Guice dans une webapp se réalise via l’installation d’un servletListener étendant GuiceServletContextListener.
l’enregistrement des ressources REST dans Guice (RESTModule)
la configuration de la base de données et son monitoring (JDBCMetricsModule)
un module pour lier Metrics et Guice (InstrumentationModule).
Vous noterez l’intégration d’un JMXReporter, et d’un ConsoleReporter dans cette configuration, qui envoie dans la sortie standard toutes les 10 secondes (à des fins de test), un descriptif des métriques.
Les ressources REST créées et les servlets Metrics disponibles seront référencées dans le fichier web.xml (ou de façon alternative via des annotations pour des containers plus récents).
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
<web-app>
<display-name>Archetype Created Web Application</display-name>
Les exemples de code d’une application Guice ayant ces annotations sont présents dans le dernier article (les annotations sont portées par des ressources Jersey).
Je vous propose dans cette série de 4 articles, de vous présenter la librairie Metrics, initié par la société Yammer. Celle-ci permet de fournir des métriques au niveau applicatif et JVM.
Ce deuxième article, présente l’intégration de Metrics dans une application web JEE. A noter que l’intégration proposée n’inclut pas, à des fins pédagogiques, une intégration facilitée via Spring ou Guice, comme c’est le cas dans le troisième article de la série.
Enregistrement du registre Metrics dans le scope application
Lors du démarrage de l’application JEE, il est nécessaire d’enregistrer dans le scope application (i.e le servletContext), le registre Metrics, pour qu’il soit disponible pour toutes les classes. Nous utiliserons pour cette tâche, un ContextListener, qui est justement exécuté au démarrage de l’application.
Pour faciliter le partage du registre, Metrics fournit un module de classes utilitaires pour les applications JEE, intitulé metrics-servlet.
Installez-donc celui-ci dans votre fichier maven pom.xml.
1
2
3
4
5
<dependency>
<groupId>com.codahale.metrics</groupId>
<artifactId>metrics-servlet</artifactId>
<version>3.0.1</version>
</dependency>
Une fois cette dépendance installée, vous pouvez étendre le InstrumentedFilterContextListener pour vous faciliter la tâche comme suit :
privatefinalstatic MetricRegistry METRIC_REGISTRY = new MetricRegistry();
@Override
protected MetricRegistry getMetricRegistry(){
return METRIC_REGISTRY;
}
}
L’installation de la classe MetricsListener effectuée dans votre fichier web.xml comme suit, vous pouvez utiliser les différentes métriques listées dans le premier article de cette série (jauge, compteur, mesure, histogramme, timer etc…).
Metrics permet aussi d’intégrer un système de “Health check”, afin de surveiller, via des appels du répartiteur de charge (load-balancer), les composants externes sur lesquels repose l’application, tels la base de données, ou le moteur de recherche par exemple. Cela permet d’avoir une idée précise, de la fiabilité de ces composants, et donc de travailler sur la tolérance de l’application aux pannes de ceux-ci.
Cette intégration est réalisée par le module maven intitulé metrics-healthchecks. Rajoutez donc dans votre fichier maven pom.xml, la dépendance suivante :
1
2
3
4
5
6
7
<dependencies>
<dependency>
<groupId>com.codahale.metrics</groupId>
<artifactId>metrics-healthchecks</artifactId>
<version>3.0.1</version>
</dependency>
</dependencies>
Puis il faut étendre la class HealthCheck pour en créer un :
resultSet = statement.executeQuery("select 1 from dual");
if (resultSet.next()) {
result = Result.healthy("'select 1 from dual' : OK");
} else {
result = Result.unhealthy("la requête 'select 1 from dual' retourne un résultat vide : KO");
}
} catch (Throwable t) {
result = HealthCheck.Result.unhealthy("'select 1 from dual' : KO ", t);
}
return result;
}
}
La création et l’enregistrement dans le registre de Metrics du healthcheck peut se faire dans la classe MetricsListener présentée précédemment. Le datasource pourra être récupérée si besoin, via JNDI.
1
registry.register("database", new DatabaseHealthCheck(datasource));
Enfin, il faut enregistrer dans le fichier web.xml, la servlet appelant les différents healthChecks enregistrés dans le registre, c’est-à-dire la healthCheckServlet :
Le load balancer appelera donc l’url http://monapplication:8080/healthcheck à intervalles réguliers sur chaque instance de webapp pour s’assurer du bon fonctionnement de tous les noeuds du cluster.
En cas de défaillance, l’instance en question sortira du pool d’instances utilisé pour répondre aux requêtes.
Exposition des mesures
Une fois les mesures posées, il faut les exposer, pour pouvoir les visualiser, et donc les analyser. Ce sont les reporters dans Metrics qui ont cette fonction d’exposition des métriques.
Via JMX
L’exposition des mesures Metrics, peut être réalisée via JMX (non conseillé par Metrics en production) par l’installation et l’initialisation d’un reporter spécifique de la façon suivante :
1
2
final JmxReporter reporter = JmxReporter.forRegistry(registry).build();
reporter.start();
Cette initialisation pourra aussi être effectuée dans le MetricsListener évoqué précédemment.
L’utilisation d’outils tels jconsole, ou visualVM, vous permettra de visualiser les mesures exposées sous forme de MBeans.
Voici un exemple de visualisation des métriques JMX via visualVM : {% img [center] /images/visualvm.png [métriques JMX via visualVM[métriques JMX via visualVM]] %}
Via HTTP
Metrics fournit par défaut, pour les applications JEE, des servlets permettant de sérialiser en HTTP le contenu du registre Metrics.
Pour obtenir ces servlets prêtes à l’emploi, il faut importer le module maven dans votre pom.xml :
1
2
3
4
5
<dependency>
<groupId>com.codahale.metrics</groupId>
<artifactId>metrics-servlets</artifactId>
<version>3.0.1</version>
</dependency>
Le module dédie expose les servlets suivantes :
MetricsServlet: expose les mesures via un objet JSON
Voici un exemple du rendu de cette servlet : {% img [center] /images/metrics-http.png [métriques JSON[métriques JSON via MetricsServlet]] %}
HealthCheckServlet : répond aux requêtes GET en exécutant tous les healthChecks enregistrés dans le registre. Cette classe est utile pour les loadBalancers, pour ne rediriger les requêtes des clients que vers les serveurs en bonne santé. Un code HTTP 200 est retourné en cas de succès, un code HTTP 500 est retourné dans le cas inverse.
ThreadDumpServlet : renvoie une représentation textuelle de tous les threads en cours sur la JVM, c’est-à-dire leur état, leur stack trace, les verrous présents etc… Cette servlet est utile à des fins de diagnostic.
AdminServlet agrège les services des servlets précédemment listées.
Les servlets listés sont certes très utiles pour exploiter une application ou aider au diagnostic d’un problème, mais elles ne sauraient être accessibles à tous.
Il est donc nécessaire, soit via votre serveur web (apache, nginx etc..), soit via votre reverse proxy, ou votre firewall, d’empêcher un accès direct depuis l’extérieur.
via d’autres canaux
d’autres reporters sont fournis par la librairie Metrics, pour exporter les métriques suivant différents canaux donc ceux-ci :
ConsoleReporter pour un export sur la sortie standard
Slf4jReporterpour un export via la façade de log SLF4J
GraphiteReporter pour stocker de façon scalable et pseudo temps-réel les métriques